Someone on your team probably brought it up in a meeting last quarter.
Maybe it was a LinkedIn post that got passed around, or a vendor demo that made the room go quiet. Agentic AI. The software that does not just follow scripts — it watches, thinks, acts. An operations manager that never sleeps and never forgets. And the pitch sounds right. You have processes that break. You have exceptions that eat hours. You have data scattered across platforms that should be talking to each other but are not. Agentic AI, supposedly, fixes all of that.
Here is what the pitch leaves out.
Table of Contents
- The Blind Agent: Why AI Needs Access to Your Data
- Not Your Data, Not Your AI
- The Central Layer: Foundation for Agentic AI
- Why Now?
- What AI-Ready Data Actually Looks Like
- The Uncomfortable Conversation
- Frequently Asked Questions
The Blind Agent: Why AI Needs Access to Your Data

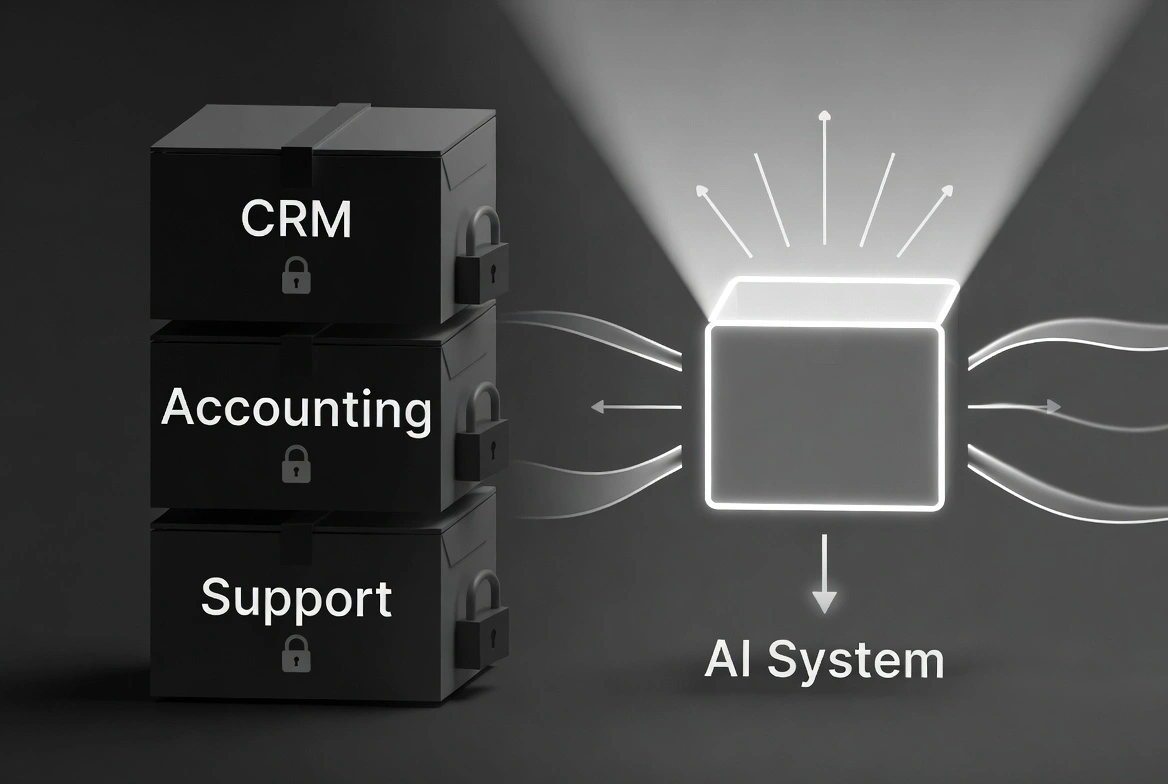
An agentic AI system is only as useful as the data it can reach. That sounds obvious until you think about where your data actually lives. Your customer records are in your CRM. Your finances are in QuickBooks or NetSuite. Your project history is on Monday or Jira. Your communications are in Outlook and Slack. Your proposals, contracts, and SOWs are in Google Drive or SharePoint. Your support tickets are in Zendesk or Freshdesk.
Each of these platforms has an API. Each API has its own authentication, its own rate limits, its own data model with quirks that the documentation either ignores or outright lies about. And each platform is holding its piece of your business like a jealous sibling who does not share.
Now imagine you deploy an agentic AI system. You tell it: “Monitor our accounts receivable. If a customer is 60 days past due and still has active support tickets, flag it for review.”
Simple request. Reasonable request. But your AI agent needs QuickBooks data AND Zendesk data AND possibly CRM data to answer it. In real time. Reliably. Every day.
Go ahead — try that with three separate API connections, three authentication tokens, three rate-limit windows, and three different ideas of what a “customer” even is.
That is the data problem nobody mentions when they talk about agentic AI.
Not Your Data, Not Your AI

We have written about this before — the uncomfortable math of data custody. Your business data is an asset. Patterns in that data, behaviors, institutional knowledge built over years — that is gold. It is YOUR gold.
But it is scattered across platforms you do not own, behind terms of service you did not read, subject to pricing changes you cannot control. You have access. You do not have custody.
And in the age of agentic AI, that distinction stops being academic and starts being existential.
Because here is the chain:
Not your data → Not your AI → Not your advantage.
The businesses that consolidate their data — that build the central layer they control — will train AI on their own history, their own patterns, their own hard-won knowledge. They will have agents that understand their specific business, not generic templates that work the same for every competitor. The businesses that do not? They will use the same off-the-shelf AI tools as everyone else. Same prompts. Same models. Same answers. No differentiation. No edge.
That is not a dramatic failure. It is a slow fade. Your competitor does not beat you because they have better AI. They beat you because their AI actually knows something yours does not.
The Central Layer: Foundation for Agentic AI

We are practitioners. We work in the trenches with small and medium businesses every day, and we can tell you that the biggest obstacle to an agentic AI project is never the AI. It is the data.
Every business we work with hits the same wall. They get excited about AI. They pick a tool or a platform. They start a pilot project. And then someone asks: “Where does the data come from?” And the room goes quiet.
The answer — the one nobody wants to hear — is that you need a central data layer. A database YOU control, on infrastructure YOU own, that consolidates the data from every platform into one queryable, consistent, AI-ready repository.
That old Microsoft Access database your company had fifteen years ago — the one built by that employee who happened to be good with computers — remember how you could ask it anything about the business? Revenue by customer? Project history? Who owes what?
You need that again. Not in Access, obviously. But the concept — one place that sees everything — is exactly what agentic AI requires to function.
Why Now?

A year ago, building and maintaining that central layer was brutally expensive. Every API connection was hand-coded. Every sync job was a custom script. Every data model mismatch was a week of debugging. Only large enterprises could justify the cost.
Agentic AI changed that math.
The same technology that makes agentic AI useful for business operations also makes it practical to build the data infrastructure that agentic AI needs. AI-assisted sync agents can handle the API quirks, the data mapping, the error recovery, the ongoing maintenance — work that used to require a full-time developer now runs on a scheduled task with a log file.
This is not theoretical. We build these systems. We have watched the time to set up a multi-platform data sync drop from months to weeks. The maintenance burden drops even further.
But — and this matters — it is still real work. Every business is different. Every combination of platforms is different. Every data model has its own surprises. Anyone who tells you there is a plug-and-play solution for this has never actually done it.
Complex does not mean impossible. It means you need someone who has been in the trenches before.
What AI-Ready Data Actually Looks Like
If you're weighing whether your business needs this kind of overhaul — including migrating older systems into a unified structure — our AI legacy system modernization work covers exactly this. Four questions to ask yourself first:
Can you answer cross-platform questions? Not “what are our open invoices” (QuickBooks can tell you that). But “which customers with open invoices also have unresolved support tickets and have not been contacted in 30 days?” If you cannot answer that today without manually exporting from three systems and building a spreadsheet, your data is not AI-ready.
Do you own a copy? If a vendor doubles their price tomorrow, or gets acquired, or sunsets their API — do you still have your data? All of it? Including the history? If the answer is “I think so” or “we could export it,” that is not custody. That is hope.
Is it consistent? Is “Acme Corp” the same entity across your CRM, your accounting system, and your project tracker? Or is it “Acme Corp” in one, “ACME Corporation” in another, and “Acme Corp.” in the third? Agentic AI is smart, but it is not psychic. Inconsistent data produces inconsistent results.
Is it current? If your central copy is a quarterly export sitting in a spreadsheet, that is not a data layer. That is a snapshot. Agentic AI needs data that is hours old, not months old.
The Uncomfortable Conversation
Most businesses are not having this conversation. They are buying AI tools and hoping the data problem solves itself. It does not.
The vendors selling agentic AI platforms are not going to tell you this. They will show you demos with clean data, unified schemas, and perfect API connections. They will not mention the six months of data infrastructure work that made that demo possible.
We will. If you are serious about agentic AI — not the demo, not the pitch deck, but actual agentic AI that does actual work in your actual business — start with the data. Build the central layer. Take custody. The AI part, honestly, is the easy part. The data is the hard part. And the hard part is where the value lives.
For a foundational comparison of agentic AI vs. traditional automation, see Agentic AI vs Automation: What's the Difference?
Alexander Birger is a technology consultant in Raleigh, NC specializing in data infrastructure and AI readiness for small and medium businesses. Learn more about our All-In AI practice.
Frequently Asked Questions
What is the “data problem” in agentic AI? Agentic AI can only act on data it can reach. Most businesses keep customer, financial, and support data siloed across separate platforms — a CRM, QuickBooks, Zendesk, Slack — each with its own API and data model. Without a way to unify that data, an AI agent can't reliably answer cross-platform questions, no matter how capable the underlying model is.
Why can't agentic AI just connect directly to my existing software APIs? It can, but each platform has its own authentication, rate limits, and quirks — and stitching together three or more live API connections for every agent task is fragile and slow. A central data layer solves this once instead of re-solving it for every new agent or workflow. Our API integration services handle this consolidation work directly.
What is a central data layer, and do I actually need one? It's a database you own that consolidates data from every platform you use into one consistent, queryable repository. If you can't currently answer a cross-platform question (e.g., “which overdue customers also have open support tickets?”) without manually exporting from multiple systems, you need one before agentic AI can deliver real value.
How long does it take to build AI-ready data infrastructure? It varies by how many platforms and how messy the data is, but AI-assisted sync tooling has cut typical timelines from months to weeks. It's still real engineering work — every combination of platforms behaves differently — which is why working with a team that's built these systems before matters.
What does “AI-ready data” actually mean? Four things: it's queryable across platforms, you own a full copy of it, entity names are consistent (no “Acme Corp” vs. “ACME Corporation”), and it's current — hours old, not a quarterly export sitting in a spreadsheet.
Is building a central data layer only worth it for large enterprises? Not anymore. It used to require enterprise-level budgets because every integration was hand-coded. AI-assisted tooling has made it practical for small and mid-sized businesses too — see our AI readiness assessment for an honest read on where your data stands today.



